Using Bayesian analysis to classify spam and non-spam was suggested by Paul Graham in his now-famous 2002 paper A Plan for Spam. A Bayesian filter takes each word in a message and looks it up in a database to see how many times that word has appeared in prior spam and non-spam messages. The Bayesian formula then lets it combine those counts into an overall probability estimate for whether the message is spam or not.
The database of word counts is produced by a training process.
You start off by giving the filter a few hundred examples of spam
and non-spam messages.
After that you watch the results; if the filter mis-classifies a message,
you flag it and the filter learns from the mistake.
After the initial training period, these filters become very accurate.
As my friend Craig put it, "It's amazing that such a simple
database application can kick spam square in the nuts."
|
SpamAssassin
is a rules-based filter written in Perl.
I used it for a while (local checks only, no damn
RBLs),
but spammers would rapidly figure out how to get around each new rule
so it was becoming less and less effective.
In version 2.5 the developers added Bayesian learning to address that problem,
but by then I had switched to bogofilter.
Besides, it's still in Perl, which means it's unmaintainable and slow.
|
bogofilter
was one of the first Bayesian filters.
Originally by über-hacker
Eric S. Raymond,
it's written in good old fashioned C and runs nice and fast.
If it has a weakness, it's that it's a little too conservative
about rating things as spam.
|
QSF
(Quick Spam Filter) is a more recent Bayesian filter.
It's also written in C and is even smaller than bogofilter.
The scores it generates seem to skew somewhat higher than bogofilter's,
to the point where it gives a lot of false positives.
Because of this I do not recommend running qsf by itself.
|
BMF (Bayesian Mail Filter) is another option. It is very small - only 4600 lines of code, 110 KB! And quite fast. In addition to SourceForge you can find it in the FreeBSD ports tree as /usr/ports/mail/bmf.
bmf's scores seem to go to the extrema, 1.000000 and 0.000000, very easily.
It's also very accurate, so that's ok.
But I'd still be uneasy about running it by itself.
|
So bogofilter is a little too lenient and qsf is too strict. Which should you use? Well, why not both? And bmf too!
You can run multiple Bayesian filters on the same mail, and have the action taken depend on the output from all of them. I am currently running three: bogofilter, bmf, and qsf. A message is classified as spam only if all filters agree that it's spam. This seems to work quite well. It's easy to set this up in procmail, since multiple patterns on the same rule get ANDed together:
# Invoke bogofilter.
:0 fw
| bogofilter -p -e
# Invoke bmf.
:0 fw
| bmf -p
# Invoke qsf.
:0 fw
| qsf -r
# If all filters agree it's spam, file it.
:0
* ^X-Bogosity: Spam
* ^X-Spam-Status: Yes
* ^X-Spam: YES
$MHDIR/spam/.
One gotcha: you must invoke bmf before qsf. This is because bmf removes all headers beginning with "X-Spam-" before adding its own headers. But qsf uses those headers too, so it needs to run after bmf or its headers get junked.
You can also use the filters to train each other. For instance, if bogofilter scores a message as 1.000000 and both bmf and qsf agree that it's spam but don't give it the higest possible score, then train bmf and qsf; and likewise for the other combinations. Here are some rules you could insert into the above, after the invocation but before the filing:
# If all filters agree it's maxi-spam, file it.
:0
* ^X-Bogosity: Spam, tests=bogofilter, spamicity=1\.000000
* ^X-Spam-Status: Yes, hits=1\.000000
* ^X-Spam-Rating: 100
$MHDIR/spam/.
# Train bmf and qsf on bogo-maxi-spam.
:0
* ^X-Bogosity: Spam, tests=bogofilter, spamicity=1\.000000
* ^X-Spam-Status: Yes
* ^X-Spam: YES
{
:0 c
| bmf -s
:0 c
| qsf -m
}
# Train bogofilter and qsf on bmf-maxi-spam.
:0
* ^X-Bogosity: Spam
* ^X-Spam-Status: Yes, hits=1\.000000
* ^X-Spam: YES
{
:0 c
| bogofilter -s
:0 c
| qsf -m
}
# Train bogofilter and bmf on qsf-maxi-spam.
:0
* ^X-Bogosity: Spam
* ^X-Spam-Status: Yes
* ^X-Spam-Rating: 100
{
:0 c
| bogofilter -s
:0 c
| bmf -s
}
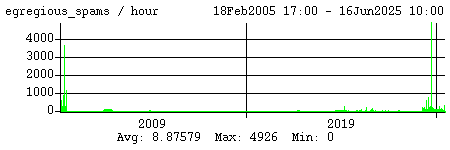
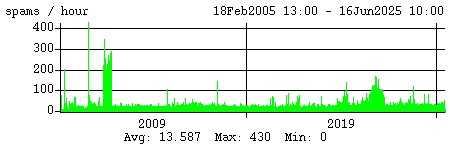
Here are some stats for spam recognized by the Bayesian filters. Egregious spam, which I score separately, means the filters gave it the highest possible scores (1.000000 and 100 respectively).
|
I have a few fake email addresses scattered around my web pages, as spam traps. The idea is for spammers to find the fake addresses by web spidering. When they send mail to the addresses, procmail routes it directly to my Bayesian filters to get registered as spam.
This worked quite well when I first started doing it in 2002, but in late 2004 the number of messages started dropping off. These days I get hardly any mail to the spam trap addresses. I'm guessing that the spammers switched their address-gathering technology from web spidering to virus propagation.
It's possible that some different methods of advertising the fake addresses would make this technique effective again, for instance putting the addresses on more popular pages that people actually visit, so they get cached on the disks of people who get virus infections. But for now I'm not using the spam traps.
| <<< [Procmail] <<< | >>> [Hall of Shame] >>> |
